Accelerating the AI Runway with an Open Data Lakehouse
Learn more about how data lakehouses enhance your AI capabilities and allow you to leverage your data resources fully.

Why every business now wants a data lakehouse
Artificial intelligence has become an essential element of how businesses work with data to transform their operations, enhance customer satisfaction, and secure a competitive edge.
If at some point, AI was just a nice-to-have, now it’s a vital component of a robust data strategy. The foundation of effective AI implementation is the availability of reliable and well-managed data that can power and scale AI initiatives. By adopting an open data lakehouse architecture, organisations can unlock the full potential of their data, to successfully adopt AI and enable more rapid and insightful decision-making.
What is data lakehouse?
Let’s look at the evolution of data lakehouse:
- A data warehouse acts as a centralised repository for extensively processed data, holding vast quantities of information.
- A data lake functions as a pool for unprocessed data, offering organisations the versatility to use and process this data according to their requirements.
- The data lakehouse emerged by integrating the superior aspects of both the data warehouse and data lake technologies, while also addressing their limitations. This integration significantly simplifies and accelerates the process for companies to derive insights from their data, irrespective of its format or volume.
- Considering the rapid progression of technology, we could soon witness an augmented, unified data analytics platform that uses generative AI to help with preparing and interpreting data as well as deriving insights from it.
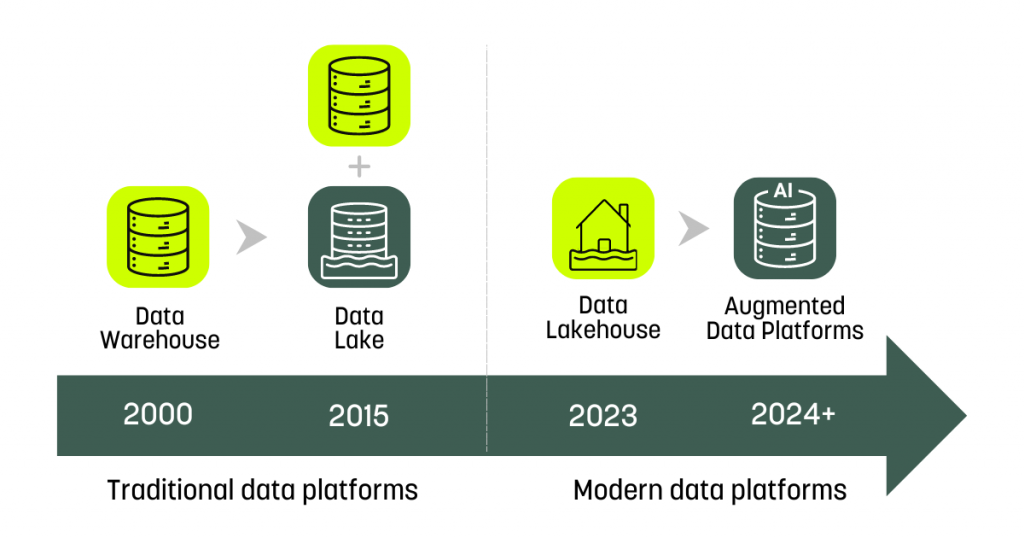
Data warehouses were great for working with structured data, like tables in spreadsheets. But they struggled with bringing in data from different places, which was a slow and complex process. Data lakes came about to hold massive amounts of messy or unstructured data — think of things like social media posts. However, turning this jumble of data into useful information could be costly and complex, and there were also worries about keeping the data safe and following rules.
So, what’s a data lakehouse? It’s a blend of a data lake and a warehouse. While offering the flexibility and affordability of a data lake, it also adds the organization, rules, and structure of a warehouse. This way, it’s easier and less expensive to manage and get insights from data.
How does data lakehouse work?
Data lakehouses are equipped to handle data ingestion using various approaches. Among them are application programming interfaces, streaming, and more. The data lands in its original, raw form without the need for schema definition. They offer a cost-effective storage solution for both structured and unstructured data, essentially housing an organisation’s entire data collection.
The technology behind data storage in lakehouses organises data into distinct zones – landing, raw, and curated – based on its readiness for use. This organisation creates a unified framework that serves as a dependable single source of truth, empowering businesses to leverage sophisticated analytics capabilities effectively.
Within the data lakehouse framework, organisations initially transfer data from various sources into a data lake. Then, some of this data is refined and transformed into more curated and reliable datasets. On these datasets, organizations set the necessary governance, usage, and access guidelines.
Why do organisations use data lakehouse?
By adopting a data lakehouse architecture, companies can enhance their data management practices through a unified data platform. This approach eliminates the need for disparate systems by removing the barriers between various data stores, leading to a more streamlined process for managing curated data sources.
The advantages of this approach include:
- Reduced management overhead — A data lakehouse centralises data from various sources, making it easily available and reducing the need for complex extraction and preparation processes typically required for data warehouses. This integration simplifies access and use of data across the organisation.
- Enhanced data governance — Consolidating data sources into a data lakehouse facilitates improved governance. A unified and standardised open schema offers better control over security, metrics, role-based permissions, and other key governance aspects, thereby streamlining management and oversight.
- Standardisation of schemas — In the past, data warehouses were developed with local schema standards due to limited connectivity, leading to inconsistency across organisations or even within different departments. Data lakehouses leverage modern open schema standards, allowing for the ingestion of diverse data types under a unified schema, simplifying data management and integration.
- Cost efficiency — The architectural design of data lakehouses separates computing and storage functions, enabling organisations to scale their storage needs independently of computing resources. This separation allows for the cost-effective expansion of data storage capabilities without requiring proportional increases in processing power, thereby offering a scalable and economical solution for data management. It can also help improve other types of costs such as:
- Maintenance and operations – simplifies management, reducing infrastructure maintenance resources.
- Data Integration and transformation – streamlines ETL processes, avoiding duplication and extra expenses.
- Data governance and security – centralises governance, improving compliance and security cost-effectively.
Real-world application of data lakehouses
According to Oracle, Experian, a multinational data analytics and consumer credit reporting company, improved performance by 40% and reduced costs by 60% when it moved critical data workloads from other clouds to a data lakehouse, speeding data processing and product innovation while expanding credit opportunities worldwide.
How does an open data lakehouse architecture support Artificial Intelligence?
AI initiatives demand systems capable of efficiently querying and handling vast amounts of structured data to improve pattern detection.
Traditionally, data warehouses were the go-to infrastructure for developing AI/ML models, thanks to their ability to quickly process queries and support the computational needs of these projects. Yet, as the volume of unstructured data crucial for AI/ML applications grows, data warehouses fall short, both in terms of handling such data and scaling cost-effectively to petabyte sizes.
Data lakes offer partial solutions by separating storage from computing, enabling the use of scalable and cost-effective object storage solutions. Despite this, they do not match the sophisticated data management and analytical tools provided by warehouses.
The data lakehouse model emerges as a solution, blending a warehouse’s analytical and processing strengths with a data lake’s scalability, flexibility, and cost-effectiveness. It serves as an integrated platform for data storage, processing, and analysis, thereby laying a strong groundwork for the management of AI models and the implementation of AI-driven projects.
Next steps for your data and AI strategy
A data lakehouse is an essential piece of the data management puzzle for any data-driven organisation.
It’s a new paradigm in data management, blending the benefits of data warehouses and data lakes and overcoming their limitations. With its capacity for flexibility, scalability, and enhanced data governance, the data lakehouse design allows businesses to fully exploit their data resources.
Take the time to ensure your business data strategy is ready for the scale of data and the impact of AI with an open data lakehouse approach.
If you’re ready to turn your marketing, customer, and business data into AI-powered tangible business growth, get in touch with our team.
Looking for more?_
Related articles

AI-driven predictive analytics: how to turn data into actionable insights


